
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 한빛미디어
- scala 2.10
- spring-batch
- springboot
- Elk
- kafka interactive query
- Elasticsearch
- Logstash
- 플레이 프레임워크
- spring-kafka
- aws
- coursera
- kafkastreams
- RabbitMQ
- statestore
- reactive
- schema registry
- avo
- kafka streams
- scala
- play framework
- Slick
- gradle
- kafkastream
- Spring
- Kafka
- confluent
- spring-cloud-stream
- enablekafkastreams
- 카프카
- Today
- Total
b
Kafka Segement 본문
#topic 생성
kafka-topics --create --topic freblogg --partitions 3 --replication-factor 1 --zookeeper localhost:2181
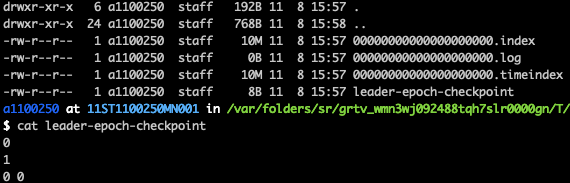
- 파일명은 base offset에 영향을 받는다 (해당 세그먼트의 첫 번째 offset) 그러므로 새로 생성된 토픽-파티션의 첫번째 세그먼트는 항상 0000000000000.log 파일명이다.

간단하게 2개의 메시지를 넣고 다시 한번 0번 파티션을 확인해보면

0000000000000.log 의 파일 크기가 변경되고 그 안을 보면 해당 데이터가 들어간것을 확인 할 수 있다
이를 좀 더 자세히 보려면 아래의 명령어처럼 세그먼트 내부를 확인 할 수 있다. ( DumpLogSegments )
~/confluent-5.2.1/bin/./kafka-run-class kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /var/folders/sr/grtv_wmn3wj092488tqh7slr0000gn/T/confluent.fDS7p2C2/kafka/data/freblogg-0/00000000000000000000.log
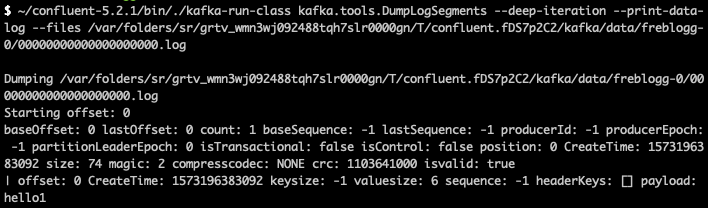
세그먼트 중에서 특기 lateset (가장 최신)의 세그먼트는 active segement 라 하고 Produce는 새로운 메시지를 active segement 에 전송한다. (즉, 가장 마지막 segement 에만 데이터를 추가한다)
카프카에서 많이 일어나는 작업은 '특정 오프셋'을 기반으로 메시지를 읽어 오는 것인데, 기본적인 세그먼트 단위 단위가 크므로 이 작업은 부담이 된다. 이 때 index 파일을 활용한다. index 파일은 '오프셋 - 물리적인 위치'를 가지고 있는 색인 파일이다. ( offset, postition 형식으로 저장이 되는듯 하다. 그래서 index file의 file size는 균일하구나?)
이 인덱스 파일에는 8바이트씩 저장이 된다. offset은 long type 8byte 임에도 4byte, 4byte 씩 저장해도 되는 이유는 filename을 기반으로 base offset을 참고하고 있기 때문이다.
example: let’s say the base offset is 10000000000000000000, rather than having to store subsequent offsets 10000000000000000001 and 10000000000000000002 they are just 1 and 2
해당 내용은 : https://thehoard.blog/how-kafkas-storage-internals-work-3a29b02e026 에서 참고함
추가
producer를 통해서 메시지를 아래처럼 넣었을 경우
> hello1
> hello2
> hello3
> a
> b
> c
$ ~/confluent-5.2.1/bin/./kafka-run-class kafka.tools.DumpLogSegments --verify-index-only --files /var/folders/sr/grtv_wmn3wj092488tqh7slr0000gn/T/confluent.fDS7p2C2/kafka/data/freblogg-0/00000000000000000000.log
Dumping /var/folders/sr/grtv_wmn3wj092488tqh7slr0000gn/T/confluent.fDS7p2C2/kafka/data/freblogg-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1573196383092 size: 74 magic: 2 compresscodec: NONE crc: 1103641000 isvalid: true
baseOffset: 1 lastOffset: 1 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 74 CreateTime: 1573197544156 size: 74 magic: 2 compresscodec: NONE crc: 4128348420 isvalid: true
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 148 CreateTime: 1573197561451 size: 69 magic: 2 compresscodec: NONE crc: 978536071 isvalid: true
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 217 CreateTime: 1573197562538 size: 69 magic: 2 compresscodec: NONE crc: 4154198374 isvalid: true
position 은 74,74, 69 바이트 증가하였다.즉 payload 가 1byte 일 경우 전체적인 포지션은 69 바이트 증가, payload 가 6byte 일 경우 포지션은 74 바이트 증가하였으므로, payload를 제외하고 68 바이트가 사용되었다 (이 68은 위의처럼 default로 사용할 경우의 이야기이지, key값을 넣는다거나, custom header 등을 넣으면 당연히 달라질것이다)
참고 :
- https://medium.com/@durgaswaroop/a-practical-introduction-to-kafka-storage-internals-d5b544f6925f
- https://kafka.apache.org/documentation/#messageformat
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
참고2 (소스레벨)
- "log.clenaer.thread" 설정 : https://github.com/apache/kafka/blob/2.3.1/core/src/main/scala/kafka/log/LogCleaner.scala#L167
- Thread Name : https://github.com/apache/kafka/blob/2.3.1/core/src/main/scala/kafka/log/LogCleaner.scala#L275
- clean logic : https://github.com/apache/kafka/blob/2.3.1/core/src/main/scala/kafka/log/LogCleaner.scala#L356