
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 한빛미디어
- Elk
- Kafka
- RabbitMQ
- avo
- spring-batch
- schema registry
- enablekafkastreams
- kafka interactive query
- scala 2.10
- gradle
- Spring
- Elasticsearch
- scala
- kafkastream
- aws
- 카프카
- Slick
- confluent
- kafka streams
- reactive
- coursera
- spring-cloud-stream
- 플레이 프레임워크
- springboot
- spring-kafka
- statestore
- Logstash
- play framework
- kafkastreams
- Today
- Total
b
Sleuth 의 Thread Tracing 본문
Sleuth는 Propagation 'B3' 타입을 기본으로 사용하여 Context 를 연결한다
B3 type은 최초개 4개의 Key를 활용하였는데 2018년 JMS, W3C에서 사용하기 위해서 'b3' 이라고 이름 지어진 단 하나의 key를 활용하는 방법도 추가 되었다 ( 링크 ) 해당 내용은 brave 의 B3-Propagation 구현에서도 찾아 볼 수 있다. 링크 를 보면 기존의 MULTI 이외에 SINGLE Format 으로 정의되었고 그 안에서 SINGLE_KEY_NAMES = Collections.singletonList(B3); 으로 활용하는 키 값을 확인 할 수 있었다.
Overall 영역을 보면 Propation 의 원리를 빠르게 이해할 수 있다. Inject 와 Extract 2개를 가지고 TraceId, SpanId 등을 계속 전파하는 것이다.
Extractor
Extractor 라는 인터페이스가 존재하지만, propagation type 이 W3C, AWS, B3가 있었던 것에 비해 B3, AWS 2개가 존재한다. (W3CPropagation 은 내부에서 직접 구현해서 사용함)
Extractor 은 Propagation type 에 따라서 기본적인 사용 방법이 달라지는데 B3Extractor은 factory 와, 대상에서 데이터를 어떻게 Get 할것인가를 구현한 Getter 의 쌍으로 구성 된다.
예를 들면 'b3' 데이터를 추출할 때 Getter<R, String> 의 getter.get(..) 을 이용한다. 이 메소드는 아래 처럼 각각 구현된다.
KafkaProducerRequest.Getter
public String get(KafkaProducerRequest request, String name) {
return KafkaHeaders.lastStringHeader(request.delegate.headers(), name);
}
brave.http.HttpServerRequest
public String get(HttpServerRequest request, String key) {
return request.header(key);
}
이렇게 Getter 를 이용해서 처음으로 'B3' 라는 Single Header 정보를 추출한다. 만약 존재한다면 파싱으로 TraceContextOrSamplingFlags 를 만들어 반환한다. 만약 B3 이라는 헤더가 없다면 전통적인 Muilti header 를 파싱해서 TraceContextOrSamplingFlags 를 반환한다.
Injector
Injector 역시 메소드 1개를 가지는 인터페이스이다. (void inject(TraceContext traceContext, R request) 처럼 Context 파라미터를 필요로 한다)
그리고 B3 는 B3Propagation.Format.MULTI, B3Propagation.Format.SINGLE enum 안에 inject 메소드가 구현되어 있고 그걸을 이용해 Setter 의 구현체의 put method를 이용해 데이터를 밀어 넣는다.
Setter 는 아래와 같은 모습의 인터페이스이다.
interface Setter<R, K> {
void put(R request, K key, String value);
}
KafkaProducerRequest 의 Setter 는 아래와 같은 모습이다. (즉 KafkaHeader 에 K,V 형태로 정보를 저장 함)
public void put(KafkaProducerRequest request, String name, String value) {
KafkaHeaders.replaceHeader(request.delegate.headers(), name, value);
}
TraceId
traceId 는 하나의 trace안의 모든 Span이 공유하는 값으로 64bit or 128bit 이다. 이 값은 configuration 으로 설정(sleuth.trace-id128) 가능 하며 기본값은 false로 64bit 체계이다. 그 외에 다른 모든 설정은 여기 에서 확인 할 수 있다.
또한 최초에 traceId 가 없을 때 첫 spanId 가 traceId 로 사용 된다.
Sleuth Async package
spring-cloud-sleuth-instrumentation 모듈안에 org.springframework.cloud.sleuth.instrument.async 패키지가 있다.
안에는 AsyncAspect, TraceRunnable, TraceCallable, LazyTraceExectuor 등이 존재한다.
TraceRunnable
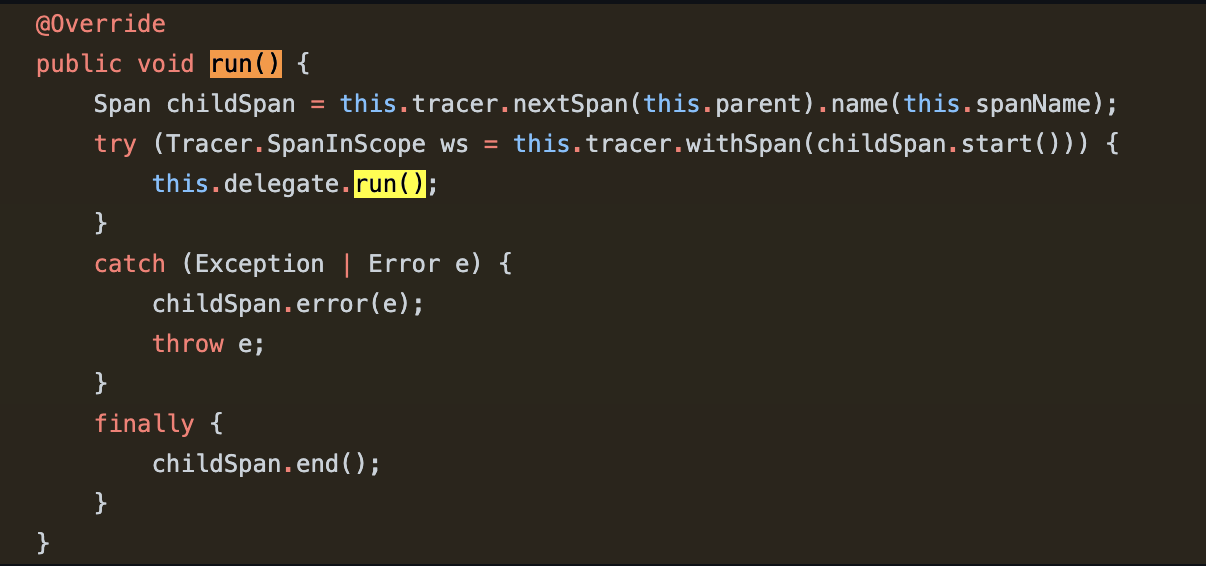
인터페이스가 아닌 클래스이고 Runnable 인터페이스의 구현체이다. Runnable 의 구현해야 할 메소드인 run() 부분을 확인해보면 알겠지만 원래 사용해야 할 Runnable 의 구현체를 'delegate' 라는 private 변수로 가지면서 앞/뒤 부분에 Span 작업을 하는 데코레이팅 코드를 구현해 놓았다. 즉, Runnable 을 바로 쓰는것이 아닌 Runnable 을 TraceRunnable 로 사용하도록 하고 있으며, Span 작업을 위해 Tracer 의 의존성을 가지고 있다.
TraceRunnable 이 생성될 때 4번째 인자로 'span 이름'을 결정할 수 있지만, 그것을 생략한다면 SpanNamer에 의해 SpanName이 결정된다. SpanNamer 의 구현체는 DefaultSpanNamer 1개가 존재한다.
TraceRunnable 이나 TraceCallable 등은 직접 사용하기 보다는 TraceableExecutorService, LazyTraceAsyncTaskExecutor 에 의해 생성된다.
TraceableExecutorService
Executors 에 많이 사용되는 ExecutorService 를 트레이싱을 지원하는 클래스이다. ExecutorService 인터페이스를 구현하며 내부적으로 ExecutorService 타입의 delegate 라는 변수를 포함한다. 이 클래스는 Tracer 자체를 가지고 있기 보다는 BeanFactory 라는 스프링 프레임웍 자체의 가장 큰 의존성을 포함하고 있다. Tracer 와 SpanNamer 를 DI 로 가져오고, SleuthContextListener 리스너가 Unusable 상태인지를 체크하기 위해 BeanFactory를 사용한다.
내부 구현은 모든 메소드를 delegate에게 위임하는 형태로 되어 있으며 Runnable 과 Callable을 TraceRunnable, TraceCallable 로 감싸는 것이 주 목적이다.