
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- coursera
- spring-batch
- Logstash
- confluent
- kafkastreams
- schema registry
- statestore
- Kafka
- kafkastream
- aws
- spring-cloud-stream
- 카프카
- play framework
- springboot
- spring-kafka
- kafka streams
- reactive
- gradle
- scala
- 한빛미디어
- Elasticsearch
- Elk
- Spring
- enablekafkastreams
- kafka interactive query
- avo
- Slick
- scala 2.10
- 플레이 프레임워크
- RabbitMQ
Archives
- Today
- Total
b
RabbitMQ 클러스터에서 큐가 존재하지 않는 노드로의 publish 와 네트워크 사용량 본문
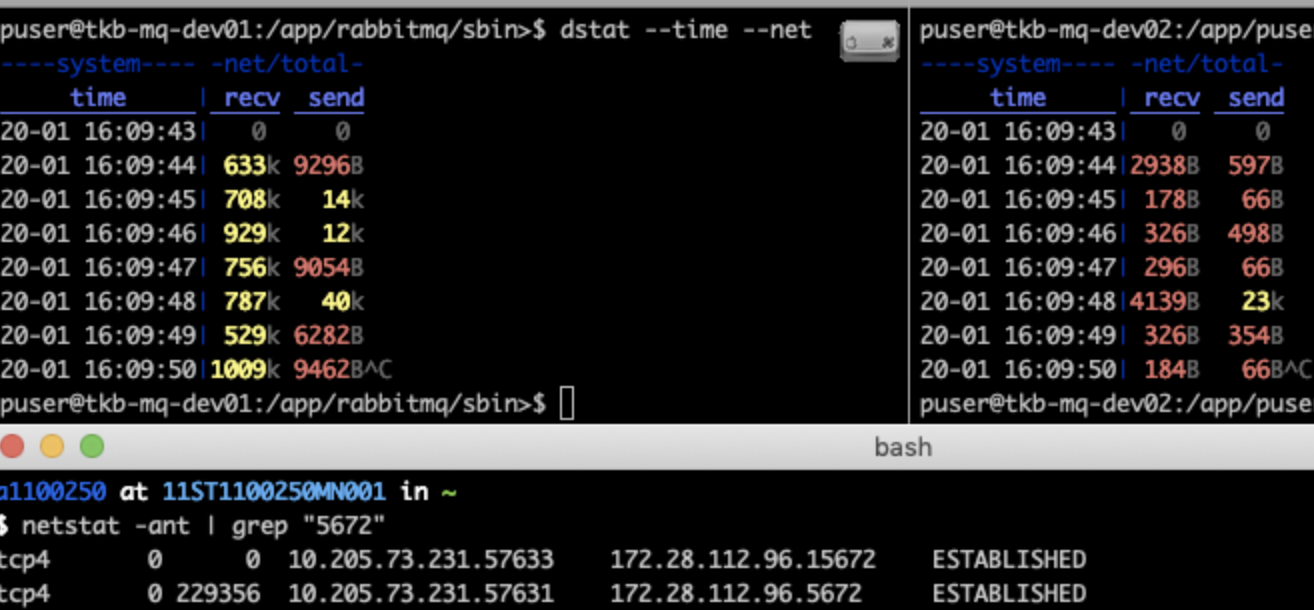
클러스터 : Node 2개로 클러스터 구성하였다.


실험) Queue는 dev01에 존재하지만 'dev02' 노드로 접속해서 데이터를 발행했다.

설명)
Queue 자체는 dev01 서버에 존재하였지만 spring.rabbitmq.address 는 dev02로 선언하였다. (처음에 메타정보를 가져와서 dev01이랑만 연결되지 않을까? 라는 예측을 했었지만 틀렸다)
위의 netstat 결과를 보면 확인 할 수 있지만 Publisher는 Queue가 없는 dev02로 접속하여서 데이터를 발행하였다.
즉, Queue가 존재하는 Node에 연결을 반드시 하지는 않는다. 클러스태 내부끼리 통신을 하여 데이터를 주고 받는 거였다. (Kafka는 해당 TopicPartition이 존재하는 Broker들과 전부 Connection 을 맺는다.)
그럼 Queue가 dev01에 있으니 publish를 dev01에 하면 네트웍이 절약이 될까? 결론은 그렇다
Comments