
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- RabbitMQ
- Elk
- kafkastreams
- springboot
- scala 2.10
- reactive
- gradle
- spring-batch
- Elasticsearch
- scala
- coursera
- 카프카
- play framework
- avo
- statestore
- kafka interactive query
- Logstash
- spring-cloud-stream
- 한빛미디어
- kafkastream
- Spring
- Kafka
- Slick
- aws
- kafka streams
- spring-kafka
- 플레이 프레임워크
- enablekafkastreams
- confluent
- schema registry
- Today
- Total
목록전체 글 (167)
b
 tomcat session 의 생성과 Tomcat session Manager
tomcat session 의 생성과 Tomcat session Manager
이 글은 StandardSession 과 StandardManager 만 대상으로 확인하였다. 톰캣의 세션은 결국 메모리 기반의 HashMap 이다. 어떻게 이 HashMap 에 Session 들이 저장되어 있고, 각 Key(SessionId)는 어떻게 발급 및 반환되는지 확인해본다. spring boot v2.6.1 에서 링크 를 보면 Lazy Session Id Generator 를 ID 생성기로 사용하는 것을 확인 할 수 있다. spring Boot 에 포함된 이 클래스는 크게 변경되는 내용은 없고, 기존의 org.apache.catalina.StandardSessionIdGenerator 를 lazy 형태로 변경한 것에 지나지 않는다 로직은 링크 를 보면 확인할 수 있지만, sessionIdLen..
 LINE 앱 ID Generator (snowflake)
LINE 앱 ID Generator (snowflake)
새로운 서비스를 구현하면서 ID Generator 가 필요하게 되었다. 대량의 코멘트가 작성될 시스템이기 때문에 이것에 대한 고민을 하였고, twitter snowflake를 약간 변경한 ID Generator 를 사용하기로 하였다. 마침, LINE 세미나에서 비슷한 주제가 있는 것을 확인하여서 해당 내용을 정리하였다. 나와 크게 다른점은 timestamp step 을 1ms 가 아닌 10ms 로 변경하여서 사용범위를 100년 이상으로 증가시킨 점 정도이다. 글로벌 유니크하고, 선형으로 커지는 ID 이고 백엔드에서 ID가 생성된다 메신저의 액티브 유저는 2억명이고, 하루 40억개의 메시지가 발행된다. 메시지가 발행될때에는 ID 가 없고, 서버에서 메시지를 받았을 때 ‘서버에서 ID를 채번’ 그리고 그 I..
스프링부트 2.5 디펜던시 업그레이드 내용 중에서 Spring Retry 1.3이 보인다. 하지만 오래전부터 1.3 버전이 사용되고 있었으며, 가장 최신 버전인 retry 1.3.1 버전은 spring boot v2.4.2 에 이미 적용이 되어 있다. retry 1.3.0 과 retry 1.3.1 을 비교해봐도 서킷 오픈에 관련된 버그 픽스를 제외하고 크게 변경 된 사항은 보이지 않는다. 단지, RetryConfiguration 클래스가 InitializingBean 인터페이스를 추가로 확장 하면서, 처음부터 초기화 된다는 점 정도이다. 여기서 언급되는 RetryConfiguration 클래스는 @EnableRetry 어노테이션에서 사용된다 (즉 @EnableRety 가 active 되면 사용되는 컨피그..
Spring Boot 2.5 is now GA 링크 : https://spring.io/blog/2021/05/20/spring-boot-2-5-is-now-ga github: https://github.com/spring-projects/spring-boot/releases/tag/v2.5.0 내가 관심있거나 필요한 부분 중에서 찾아 본 것들 schema.sql and data.sql 관련해서 "spring.datasource.*" 이 "spring.sql.init.*" 으로 re-design https://github.com/spring-projects/spring-boot/issues/25323 . https://github.com/spring-projects/spring-boot/commit/90..
 Sleuth 의 Thread Tracing
Sleuth 의 Thread Tracing
Sleuth는 Propagation 'B3' 타입을 기본으로 사용하여 Context 를 연결한다 B3 type은 최초개 4개의 Key를 활용하였는데 2018년 JMS, W3C에서 사용하기 위해서 'b3' 이라고 이름 지어진 단 하나의 key를 활용하는 방법도 추가 되었다 ( 링크 ) 해당 내용은 brave 의 B3-Propagation 구현에서도 찾아 볼 수 있다. 링크 를 보면 기존의 MULTI 이외에 SINGLE Format 으로 정의되었고 그 안에서 SINGLE_KEY_NAMES = Collections.singletonList(B3); 으로 활용하는 키 값을 확인 할 수 있었다. Overall 영역을 보면 Propation 의 원리를 빠르게 이해할 수 있다. Inject 와 Extract 2개를 ..
 DGS(Domain Graph Service) Netflix
DGS(Domain Graph Service) Netflix
2021/02/08 현재 v3.3.0 이 릴리즈 되었다 이 버전은 Spring Boot 2.3.6.RELEASE 와, Spring Cloud 는 Hoxton Relase에 의존성을 가지고 있다 ( git.io/JtVCs , 음.. ilford 맞추려면 얼마나 삽질을 해야 할까 ... ㅠ) 그리고 3.3.0 버전은 jcenter 에만 올려져 있으니 repository에 jcenter를 추가해야한다. (TMI : Jcenter는 2/4분기에 없어진다) 기본이 되는 library 는 "com.graphql-java:graphql-java:15.0" , "com.graphql-java:java-dataloader:2.2.3" 이다. Data Fetcher 데이터를 서빙하는 코드는 netflix.github.io..
SpringBoot v2.3.1 기준 (Spring Data Jdbc 는 2.0.1.RELEASE) 으로 쓰고 있지만.. 적당한 규모의 엔터프라이즈 서비스에서도 무리가 없다. 이 이상 복잡하게 사용해야 한다면... Jdbc 의 사상을 이해하지 못하거나, 처음부터 JPA나 그냥 Spring Jdbc 를 선택했어야 할 것이다. 하지만 다른 팀원에게도 SpringDataJdbc를 추천할 수 있을지 모르겟다... 제일 큰 문제는 stackoverflow ㅎㅎㅎㅎ Issue Count 1800 610 Commit 1450 630 Main Contributors 2~3 2~3 동일한 컨트리뷰터가 기여중이다. 1. https://github.com/mp911de 2. https://github.com/schauder..
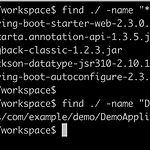 SpringBoot 2.3 를 이용해 생성된 도커의 내부 구조
SpringBoot 2.3 를 이용해 생성된 도커의 내부 구조
스프링부트 2.3이 되면서 CloudFoundry Buildpack을 기반으로 해서 도커 이미지를 만들 수 있게 되었다. > spring.io/blog/2020/01/27/creating-docker-images-with-spring-boot-2-3-0-m1 > spring.io/blog/2020/08/14/creating-efficient-docker-images-with-spring-boot-2-3 데모는 위의 래퍼런스 문서들을 따라하면 된다. 1. 이를 위해서 Gradle Task 와 Maven Mojo 가 각각 추가 되었다. 메이븐 spring-boot:build-image 링크 그래들 bootBuildImage 링크 2. 실제로 도커 이미지를 생성 해보면 base image 가 docker.io..